

- zembed-1 pareto outperforms voyage-4 on almost all verticals in accuracy
- zembed-1 is more robust than voyage-4 to unclean prod-like data, showing smaller degradation from clean documents
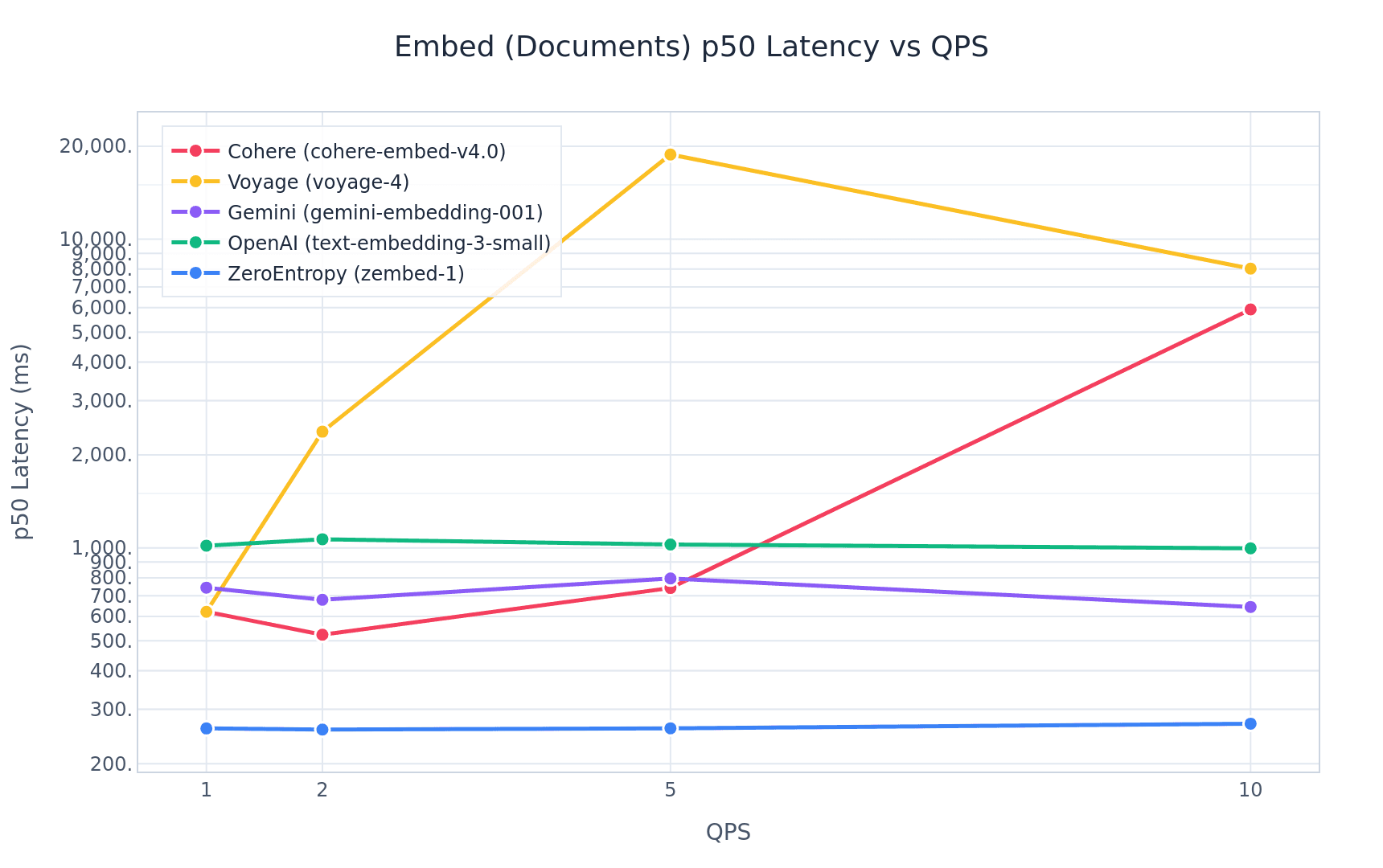
- At 2 QPS, zembed-1 offers a P50 latency of 280 ms. Voyage offers 2500ms.
- zembed-1 costs $0.05/million tokens (currently reduced to $0.025 until June 1st!), voyage-4 offers at $0.06/million tokens.
SOTA Accuracy: A Tale of Two Models
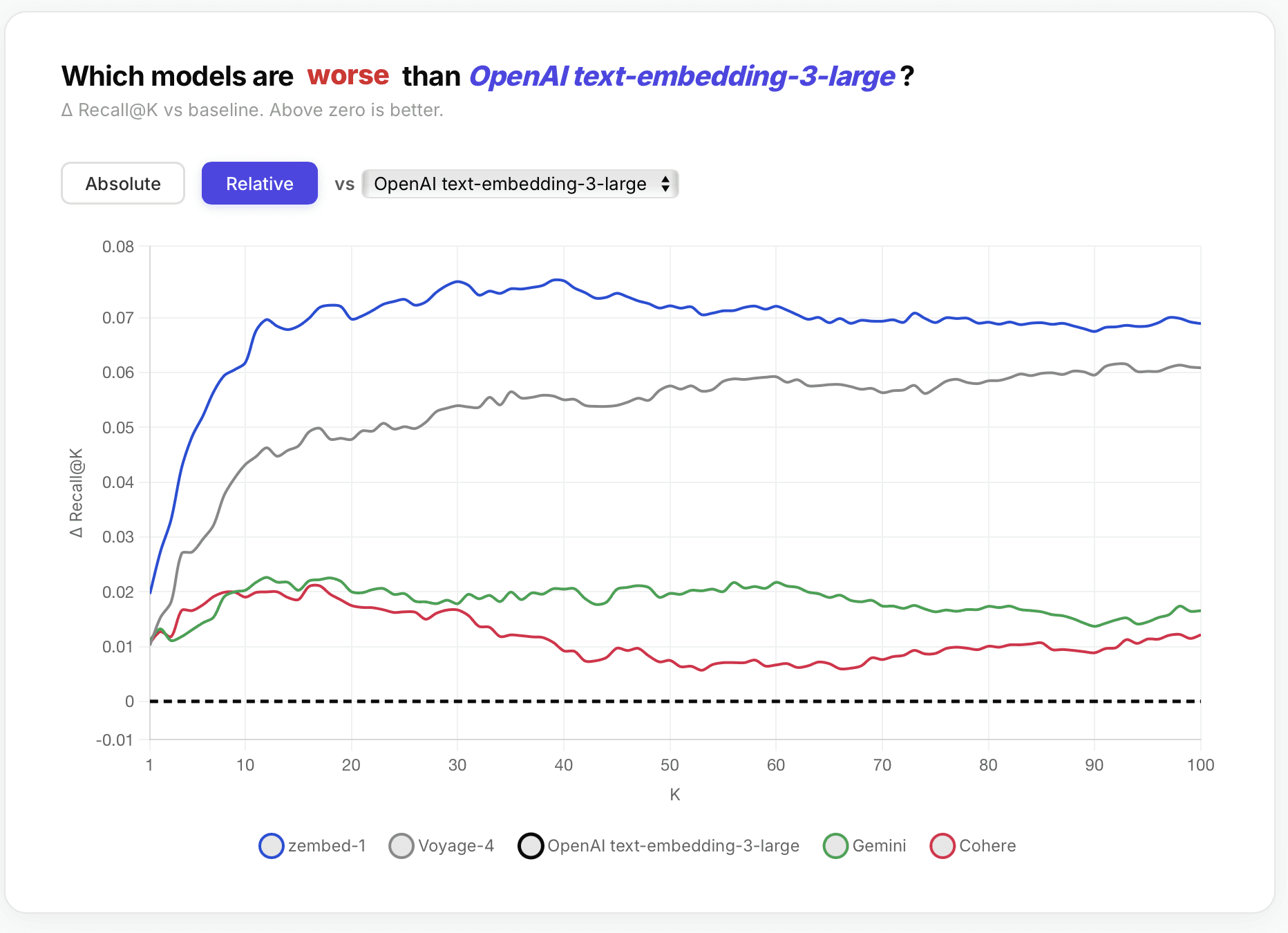
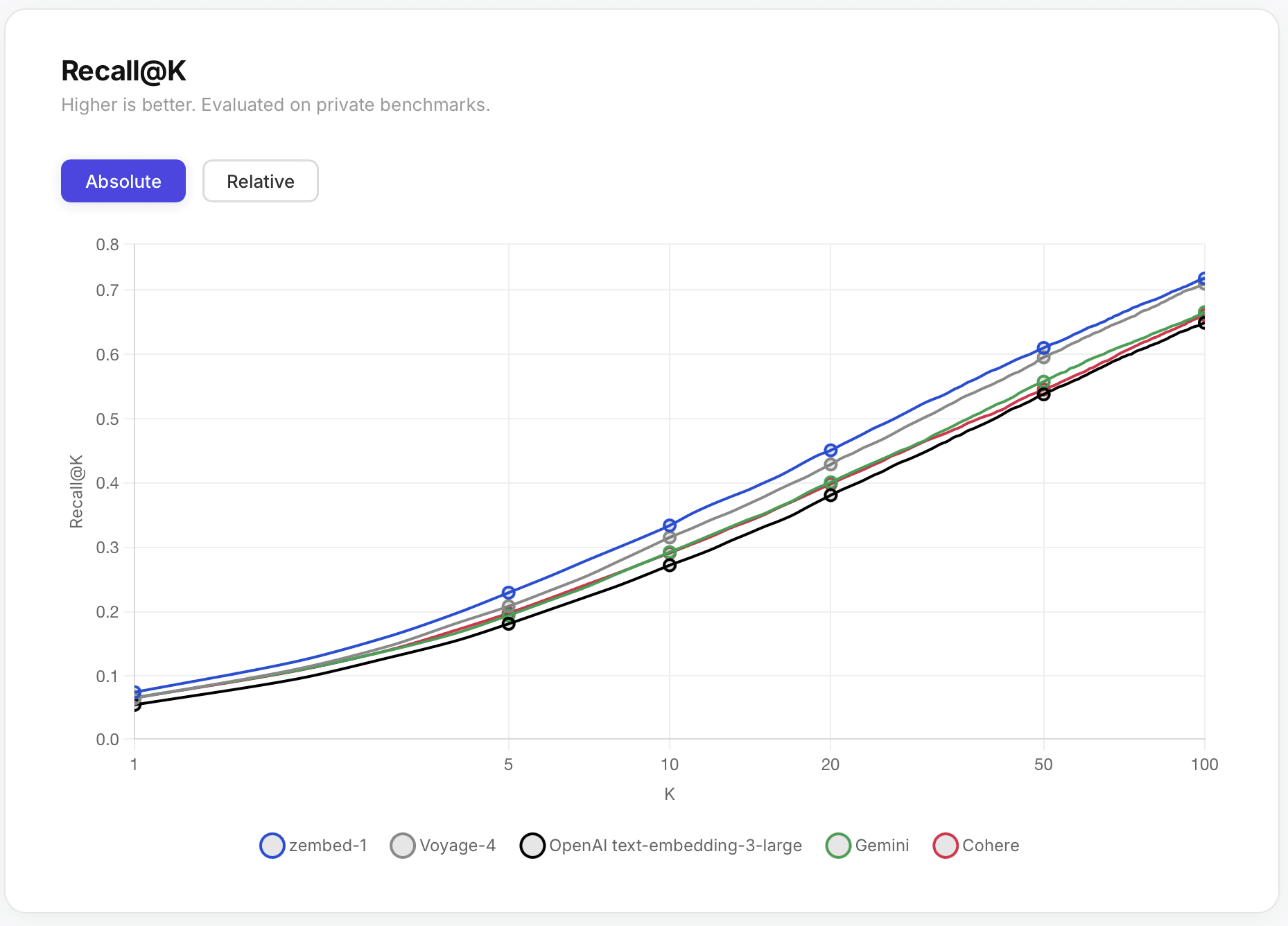
On our evaluations we found that of the various flagship models, two consistently outperformed the rest: zembed-1 and voyage-4, exceeding other models such as cohere embed v4 or openai v3 large by 5-7%+ Recall@100 across all verticals.
If the bottleneck on your agent or application is accuracy, the choice is essentially between these two options. So how do they compare in a head-to-head matchup? For the below we use the same evals as on our zembed-1 launch blog post.
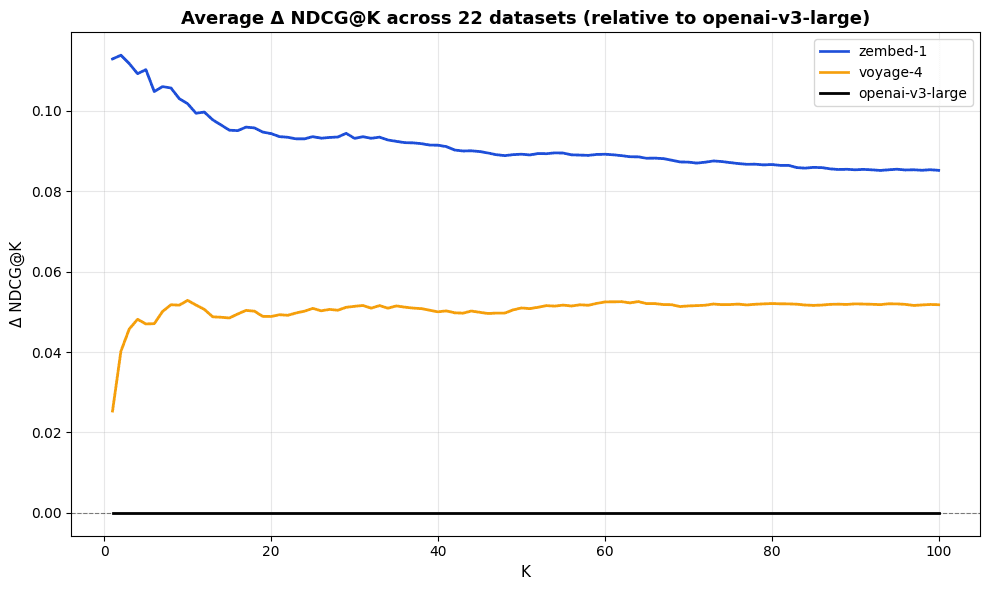
Across 22 evaluation datasets, zembed-1 outperforms voyage-4 at NDCG@10 on 18 of them.
The composition of these 22 datasets is as below.
| Number of Datasets in Vertical | Verticals |
|---|---|
| 4 | Technology, Enterprise |
| 3 | Healthcare, Finance, Hospitality |
| 2 | Industrial |
| 1 | Academia, Recruitment, Legal |
Latency
Our figures here, as in our launch blog post, were calculated using our open source latency benchmarking platform. This is the same code testing each endpoint, with no inherent advantage to any company. We encourage you to try it out yourself and see what results you get!
At 1 QPS, voyage-4 has 2.3x higher P50 latency, and at 2 QPS, that gap widens to 70x. (Yes, really)
It is… useful to keep in mind that great models and great infrastructure can prove orthogonal components.
Robustness to Messy (AKA Prod-Like) Data:
Production Data is rarely clean — chunking can fragment context across snippets, imperfect data cleaning (especially of web data) can add unrelated information, and synthetic transformations can misrepresent source text. Thus, a simple question for users concerned about how clean public benchmark results might translate to actual production performance might be as follows:
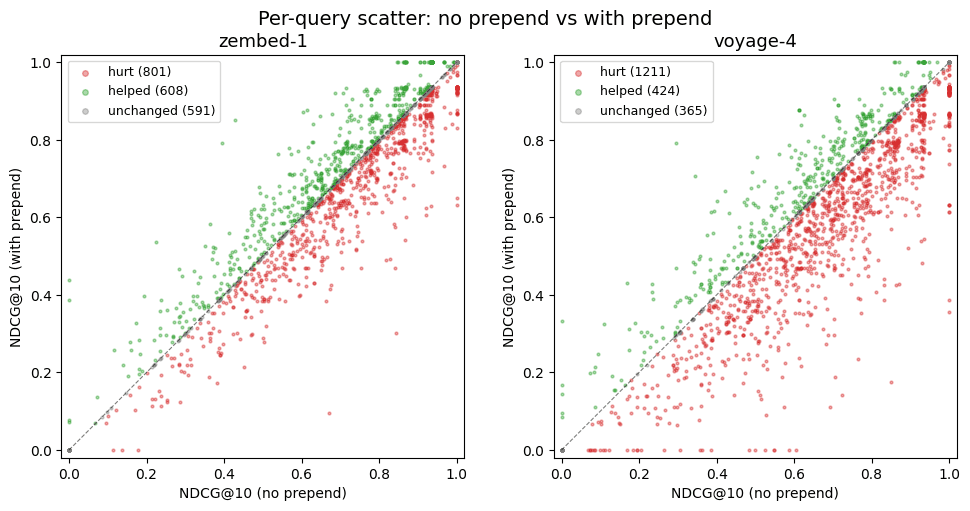
What happens to NDCG@10 performance when we prepend unrelated information to each query, or to each document?
For our testing purposes, we prepended the below string to every query in the corpus and re-ran evals:
PREPEND_SENTENCE = "Irrelevant statement: Water bottle flipping contest. \n\n Query: \n\n"
Now, given the geometry of embedding models, we would naturally expect some degradation, but a strong desideratum would be to minimize it for the purpose of robustness to messy, prod data. zembed-1 indeed exhibits this degradation, going from 0.738 to 0.729 (Δ-0.009) NDCG@10 on the popular public dataset CureV1. Voyage-4 goes from 0.687 to 0.633 (Δ-0.054).
Voyage-4 thus exhibits a degradation five times larger than zembed-1.
Direct Pairwise Comparison on Query, Doc1, Doc2 Triplets:
But what about on specific pairs of (query, document) scores that zembed-1 and voyage-4 disagree on? When the two frontier models disagree, who is generally correct?
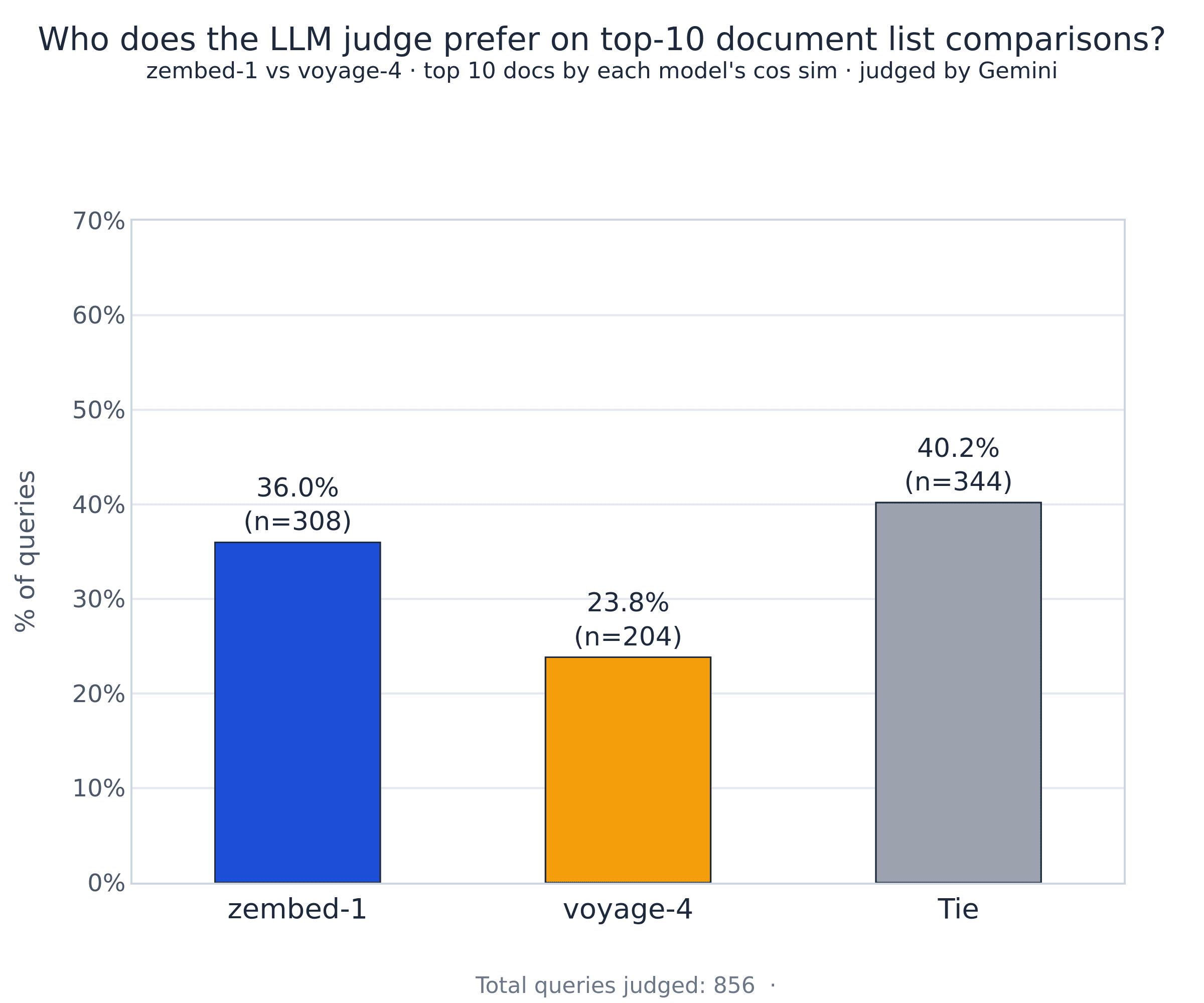
If we simply take the top ten documents by zembed cosine similarity and similarly by voyage, and send both to gemini, asking it which is better, we observe a 12% gap in favor of zembed on listwise comparison.
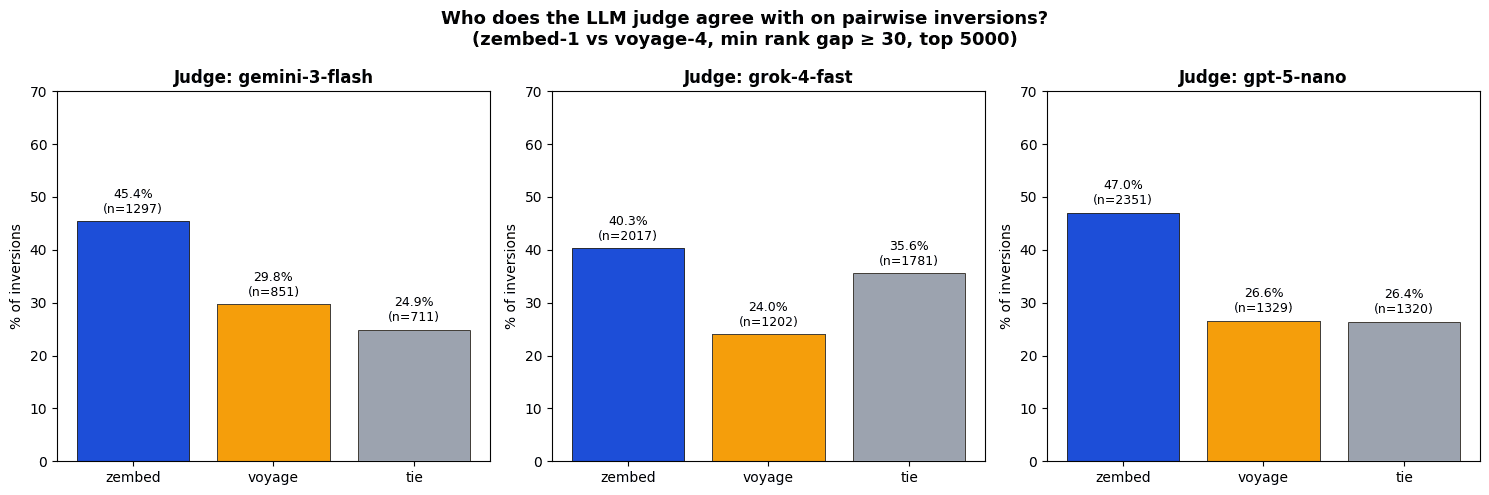
A more sophisticated analysis is presented now: On an agglomeration of 14 public datasets (notably fiqa, bioasq, cosqa), we took the top 100 documents by cosine similarity to all queries for both voyage-4 and zembed-1 on every query. We then identified pairwise ranking inversions — pairs of documents (d₁, d₂) where the two models disagree on which of the two is more relevant to a query q, with a rank gap of at least 30 positions. We then sent that (q,d1,d2) to gemini-3-flash, gpt-5-nano, and grok-4-fast-non-reasoning, asking which of the two documents was more relevant to the query.
A 15-20% differential in favor of zembed-1 is consistently observed.
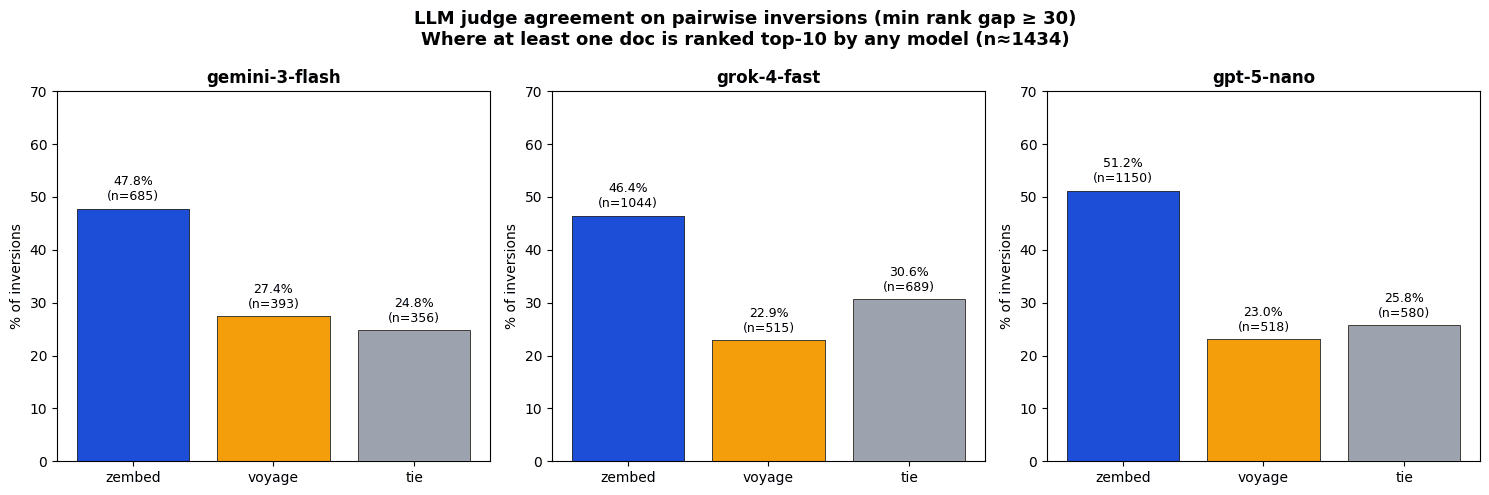
When we filter for the cases which will most affect production performance (those where either zembed or voyage determined one of the documents to be in the top 10) the gap becomes even larger, at 27%-33%.
What Embedding Model is Best for Me?
Choosing an embedding model has traditionally been a trade-off between accuracy, expected latency, and cost. zembed-1 pareto-dominates every other frontier embedding model on accuracy, and strongly over-performs voyage-4 across verticals. No other provider offers latency as consistently low (Cohere P50 is 2.3x, OpenAI is 3.5x, Voyage is 2.3x + failed requests). And at $0.05 per million tokens (Cohere 24x, OpenAI 2.6x, Voyage 1.2x), SOTA search has never been more affordable.
But what if your use case is even more cost-sensitive, and you’re willing to sacrifice a few NDCG points for massive storage cost reduction? With zembed-1’s quantization offerings, you can control that trade-off directly and exactly.
Quantize your embedding to binary, for example, and get a massive -94% storage cost reduction while still enjoying 89% performance of zembed-1 (as accurate as openai v3 large).
Get Started
Get Started
zembed-1 is available today through multiple deployment options:
from zeroentropy import ZeroEntropy
zclient = ZeroEntropy()
response = zclient.models.embed(
model="zembed-1",
input_type="query", # "query" or "document"
input="What is retrieval augmented generation?", # string or list[str]
dimensions=2560, # optional: must be one of [2560, 1280, 640, 320, 160, 80, 40]
encoding_format="float", # "float" or "base64"
latency="fast", # "fast" or "slow"; omit for auto
)Documentation: docs.zeroentropy.dev
HuggingFace: huggingface.co/zeroentropy
Get in touch: Discord community or contact@zeroentropy.dev
Talk to us if you need a custom deployment, volume pricing, or want to see how zembed-1 + zerank-2 performs on your data.



